当我们惊叹于智能手机的语音助手对答如流、沉醉于电商平台精准推荐心仪好物、享受着自动驾驶汽车缓缓驶来的时候,我们正在体验人工智能(AI)带来的巨大便利。然而,你是否曾想过,这些看似拥有“智慧”的机器,是如何学会识别图像、理解语言、做出决策的?答案的核心,隐藏在一个看似简单却至关重要的环节——数据标注。
一、什么是数据标注?
我们可以把一个AI模型想象成一个天赋异禀但一无所知的“婴儿”。它拥有强大的学习能力,但需要有人来教它认识这个世界。数据标注,就是这个“教”的过程。
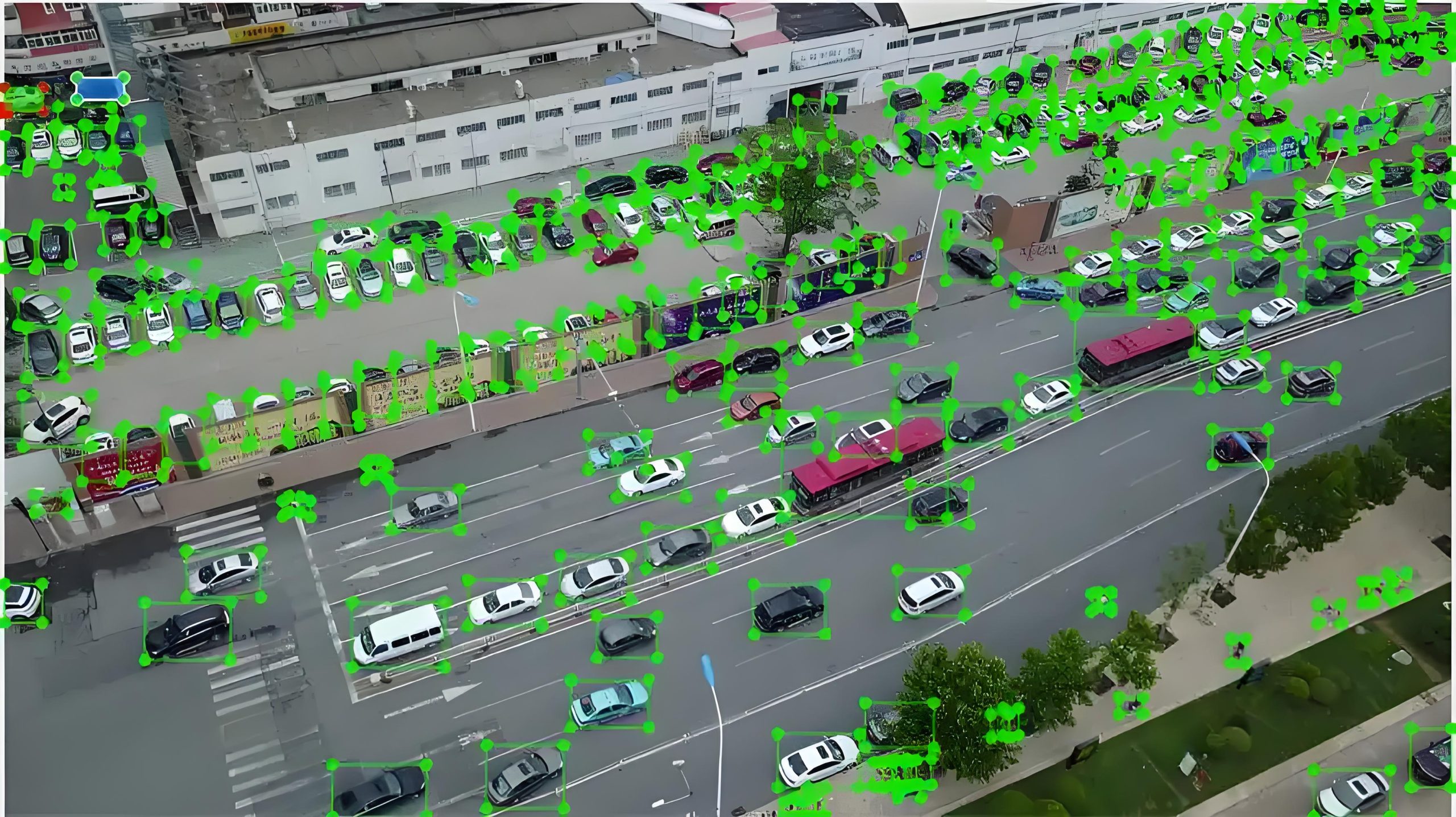
具体来说,数据标注就是给原始数据(如图片、文本、语音、视频)打上标签,做出注释,告诉AI模型这些数据是什么、有什么特征、属于哪一类别。这些被标注好的数据就成为了一份“标准答案”或“教材”,AI模型通过反复学习这些教材,才能逐渐掌握识别和预测的规律。
例如:
- 在一张街景图片中,标注员需要框出所有的汽车、行人、交通标志,并分别打上“汽车”、“行人”、“红灯”等标签。
- 在一段语音中,标注员需要将说出的话一字不差地转写为文字。
- 在一段商品评论中,标注员需要判断其情感倾向是“正面”、“负面”还是“中性”。
正是这些大量、细致、准确的标注工作,为AI模型提供了学习的基石。
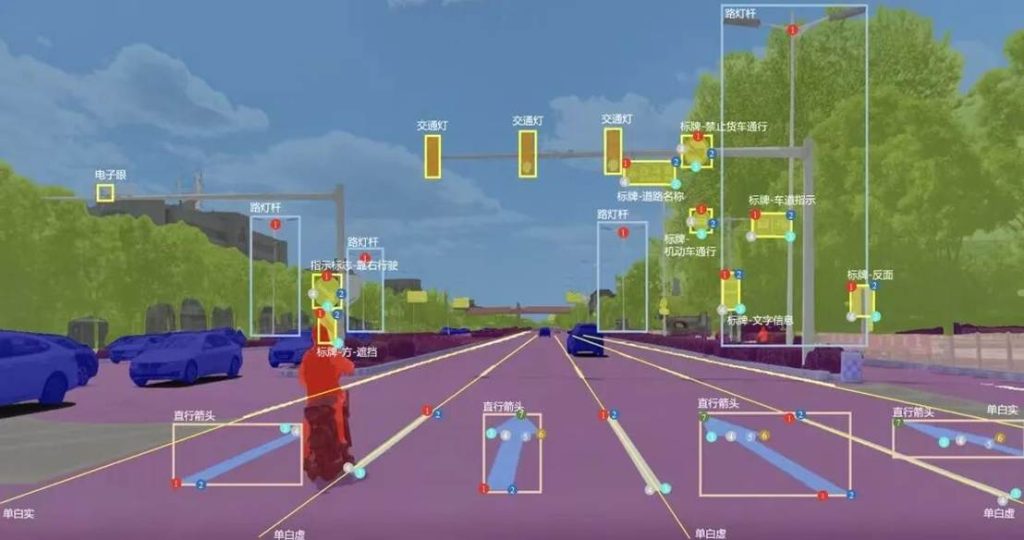
二、为什么数据标注如此重要?
“垃圾进,垃圾出”(Garbage In, Garbage Out)是计算机科学领域的经典法则,在AI领域同样适用。一个AI模型的能力上限,很大程度上取决于其训练数据的质量和数量。
- 质量是生命线:如果标注数据错误百出,比如把猫标注成狗,把负面评论标注成正面,那么AI模型学到的就是错误的知识。基于这些错误知识做出的预测和判断,其结果可想而知。高质量的标注数据是训练出可靠、可信AI模型的根本保证。
- 数量是基础:AI模型需要学习大量的例子才能举一反三,泛化到未见过的场景中。要让一个模型能识别世界上的各种猫,就需要提供成千上万张不同品种、不同姿态、不同光线下的猫的图片供它学习。没有足够的数据量,模型就无法获得“经验”,容易陷入“过拟合”(只会认训练过的图片,遇到新图片就傻眼)的困境。
因此,数据标注是AI产业不可或缺的一环,是连接原始数据和智能算法的桥梁,被誉为AI的“基石”和“燃料”。
三、数据标注是如何进行的?
数据标注通常是一个由“人机协同”完成的过程。
- 任务分发:项目管理者将大量的原始数据和详细的标注规则(标注手册)分发给标注员。规则必须极其精确,以确保不同标注员做出的判断标准一致。
- 人工标注:标注员根据规则,使用专业的标注工具(如标注平台提供的在线软件)对数据进行处理。这是目前保证标注质量的核心环节,需要标注员集中注意力并具备一定的理解能力。
- 质检与验收:标注完成的数据会经过多轮质检(QC),由资深的审核员进行检查和抽检,确保准确率达标。不合格的数据会被退回修改。
- 算法辅助:随着技术发展,越来越多的自动化工具被用于辅助标注。例如,在已经标注了1000张猫的图片后,预训练模型可以初步预测新图片中的猫,标注员只需进行修正和确认即可,这大大提升了效率。这就是“人机循环”(Human-in-the-loop)的模式。
四、挑战与未来
数据标注行业也面临着一些挑战:成本高企(尤其需要高质量标注时)、流程繁琐、对标注员的技能和耐心要求高等。同时,如何标注更具主观性的数据(如艺术审美、情感细微差别)也是一个难题。
展望未来,数据标注的发展趋势是:
- 自动化与智能化:通过主动学习、半监督学习等技术,减少对人工标注的依赖,让模型更多地自主学习和提出疑问。
- 专业化与精细化:随着AI向医疗、法律、科研等专业领域渗透,标注工作也需要更多领域专家的参与。
- 标准化与伦理化:建立更统一的行业标准和质量体系,并更加关注数据隐私和标注员的权益保障。