
在人工智能与高性能计算(HPC)加速演进的背景下,算力需求正以前所未有的速度增长,传统摩尔定律的延展已无法单独支撑这一趋势。先进封装技术因而走到前台,成为决定系统性能、带宽与能效的关键变量。TSMC 在这一领域的核心布局,是以 CoWoS® 和 SoIC® 为底座,提供多形态的异构芯粒集成方案,并进一步将电光融合的 COUPE 光引擎 纳入体系,从而推动 CPO(Co-Packaged Optics) 的落地。
报告《Advanced CPO Integrated by CoWoS® and COUPE》展示了 CoWoS® 平台在中介层扩展与 HBM 堆叠上的能力,解析了 COUPE 光引擎的结构创新与光学性能,勾勒了 CPO 的功耗与时延曲线演进,并提出 >200T 带宽路线图与产业协同需求。其核心观点在于:先进封装不只是延伸摩尔定律,而是在重构系统边界。
原报告我放在了知识星球
以下是对报告内容的梳理总结——————————————
一、CoWoS®:HPC/AI 异构集成的算力底座
在算力需求持续爆炸的时代,先进封装已成为推动 AI 和 HPC 系统性能扩展的核心底座。TSMC 的 CoWoS®(Chip-on-Wafer-on-Substrate),作为通用 2.5D 异构芯粒集成平台,正承担起这一历史使命。
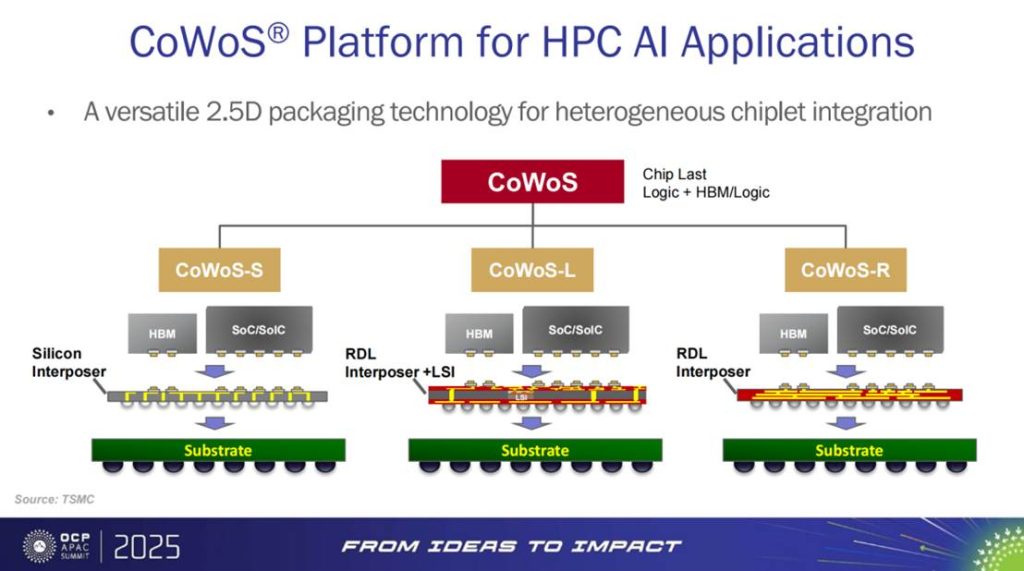
CoWoS® 的核心优势在于其多形态架构:CoWoS-S、CoWoS-L、CoWoS-R。不同分型在中介层材料、RDL 扩展方式以及与 LSI 的结合路径上各有侧重,既能满足高性能 SoC 与 GPU 的超大芯粒需求,又能为多颗 HBM 的堆叠提供灵活支撑。换句话说,CoWoS® 不是单一产品,而是一套覆盖不同算力场景的系统性解决方案。
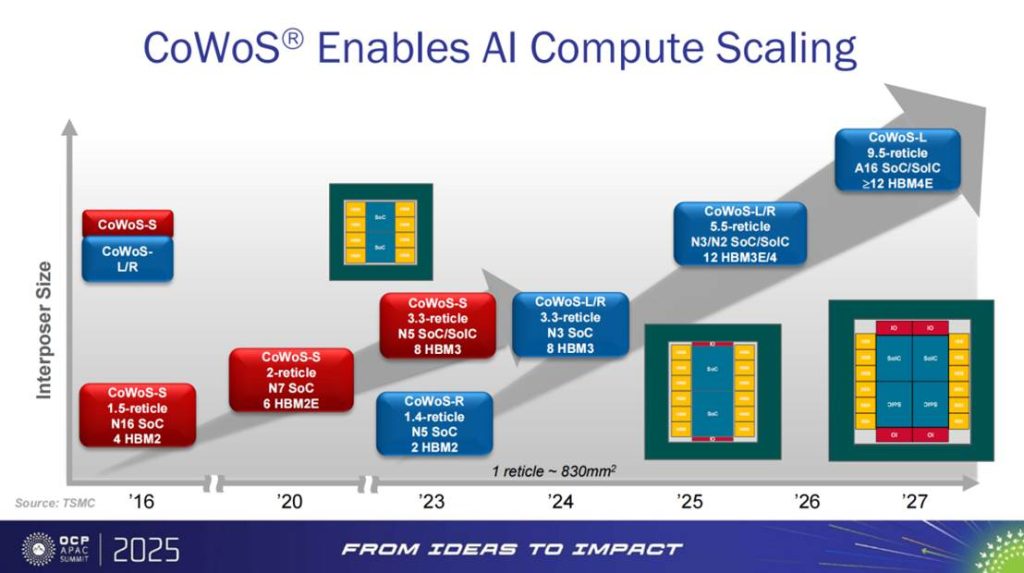
推动 HPC/AI 持续扩展的关键,在于中介层面积的迭代升级。报告显示,CoWoS® 的有效尺寸已经从约 1.5 reticle → 2 → 3.3 → 5.5 → 9.5 reticle,伴随制程节点从 N7、N5、N3、N2 直至 A16 的演进。这一“视场/拼版”扩张直接带动了 HBM 的扩容:从早期 4/6 颗逐步提升至 8 颗、12 颗乃至 ≥12 颗 HBM3/3E/4E。这意味着系统级带宽与算力密度成倍增长。资本开支暴增背后,实质上是中介层面积和 HBM 堆叠数的“几何级跃迁”。
与此同时,CoWoS® 与 SoIC® 的结合,让异构集成进一步突破单芯片封装的天花板。通过直接 3D 叠合 SoC 与存储或互连芯片,CoWoS® 不仅提供了横向的带宽扩展,更引入纵向的计算与存储协同。这种“水平拼接 + 垂直叠合”的模式,使 AI 训练集群的能效与规模扩展获得前所未有的灵活性。
本质上,CoWoS® 已从单纯的封装方案,演变为 HPC/AI 的算力操作系统底盘。它以大尺寸中介层为核心,支撑芯粒化计算的自由组合,并通过代际演进不断推高算力与带宽上限。正如报告所揭示:“先进封装不是延伸摩尔定律,而是在重构系统边界。”
二、COUPE:以 SoIC® 为核心的紧凑型光引擎
随着算力密度的跃迁,传统电互连在带宽与功耗上的瓶颈愈加凸显。TSMC 推出的 COUPE(Compact Universal Photonic Engine),正是面向这一挑战的战略解法。它基于 SoIC® 技术,将 EIC(电路集成芯片) 与 PIC(光子集成芯片) 直接堆叠,从而实现紧凑体积、高能效比与优异的电光协同性能。

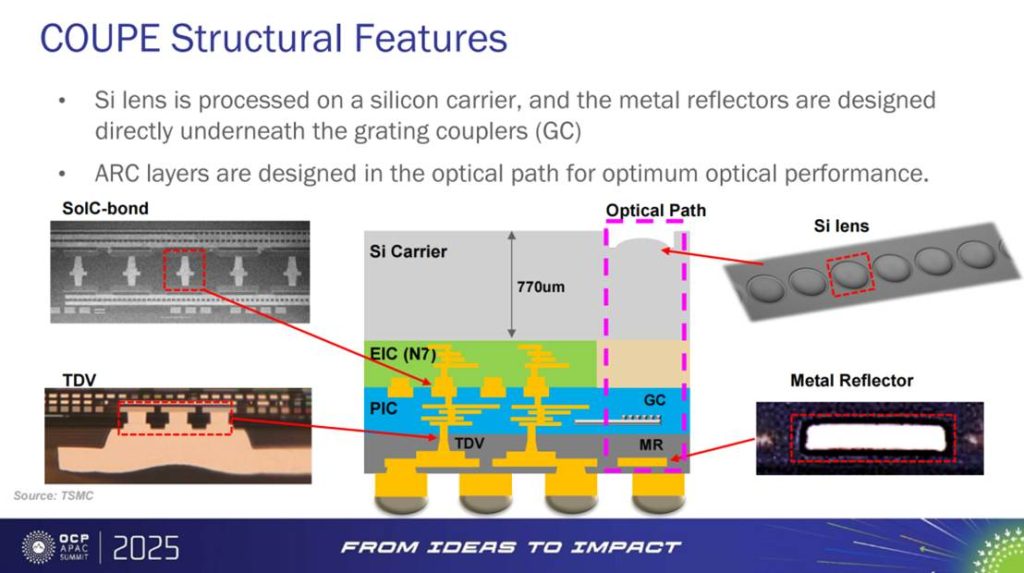
COUPE 的结构设计极具工程美学。其光学路径在 硅透镜(Si lens)+ 金属反射镜(metal reflectors)+ 抗反射涂层(ARC) 的协同下被优化至极致:硅透镜实现光的聚焦与准直,金属反射镜在光栅耦合器(GC)下方增强反射效率,而 ARC 则有效抑制反射损耗。这一“镜—透—膜”的三重结构,使得光路损耗大幅降低。
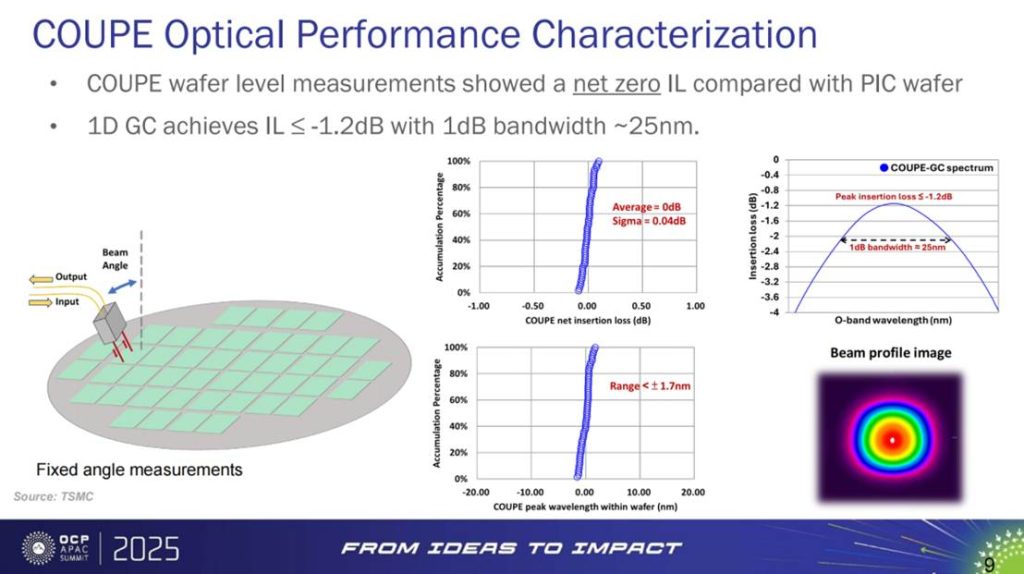
从实验数据看,COUPE 的表现堪称“零损耗方案”。在晶圆级量测中,其相较基线 PIC 的插入损耗(IL)实现了 净零差异。同时,1D 光栅耦合器(1D GC)达到 ≤ −1.2 dB 的 IL,且在 约 25 nm 范围内保持 1 dB 带宽。这意味着 COUPE 不仅解决了光引擎的小型化问题,更将其性能推向大规模实用化的门槛。
相比传统独立封装的光模块,COUPE 的最大价值在于其系统集成逻辑。借助 SoIC® 的超高密度互连,EIC 与 PIC 可在亚微米尺度下无缝耦合,极大缩短电—光转换路径,从而降低功耗与延迟。简而言之,“把光拉到芯片边缘,系统功耗曲线便被重新改写。”
COUPE 的出现,意味着光学不再是外围接口,而是深度嵌入 HPC/AI 的核心封装体系。它不仅提升了每比特能效,更为未来 CPO(Co-Packaged Optics) 奠定了坚实的光学引擎基础。可以说,COUPE 是 HPC/AI 光互连时代的“点火器”。
三、CPO 形态演进:从铜线到“光近算”
数据中心的演进史,某种程度上就是互连方式的迭代史。从最初的铜线,到插拔式光模块,再到基板级光引擎,如今迈向 中介层级的 CPO(Co-Packaged Optics),每一次迁移都重塑了功耗与时延的曲线。
最早的 铜线互连,在带宽不足与功耗剧增的双重制约下,逐渐退出高性能舞台。随后,板卡级 OE(Optical Engine) 通过可插拔光模块实现了初步解耦,功耗效率降至 >10 pJ/bit,但依旧远高于系统可持续所需水平。进入 基板级 OE 阶段,功耗进一步下探至 >5 pJ/bit,时延也降至 小于 0.1X。而当光学被移入中介层、实现真正的 CPO 集成 时,能效跃迁至 >2 pJ/bit,时延骤降至 <0.05X。
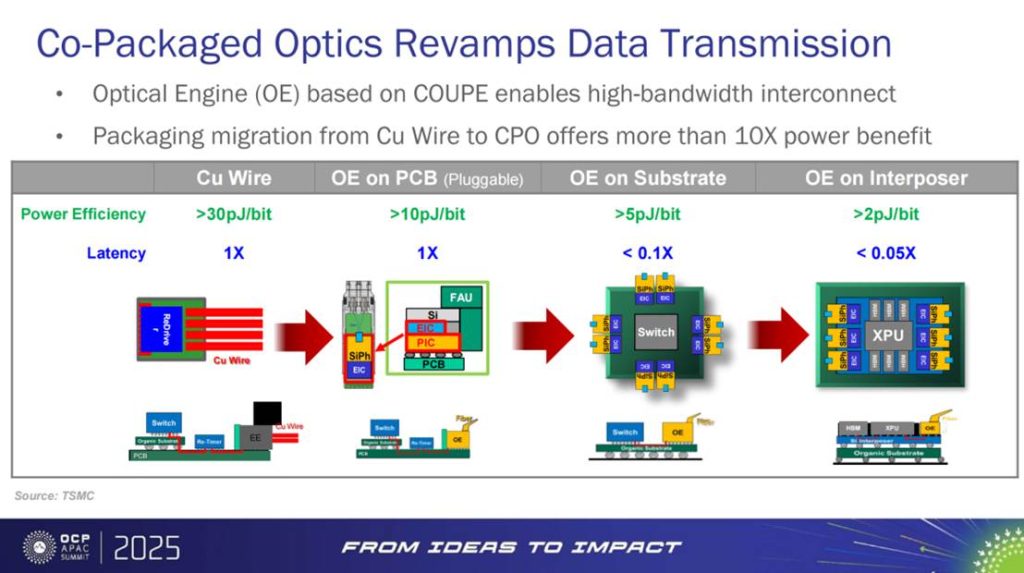
这不仅是数字的迭代,而是一种 范式转移。功耗的数量级降低意味着,互连不再是限制算力扩展的“能耗黑洞”;而时延的大幅缩短,则让光近算成为可能。正如报告中的图示所揭示:CPO 提供了超过 10 倍的能效收益,并在延迟维度实现了数量级优化。
其背后的逻辑十分清晰:“把光拉近计算,功耗就把系统拉回可持续轨道。” 这是 CPO 相对铜线与传统 OE 最大的价值主张。它不仅解决了高带宽互连的物理极限,更为未来百 Tbps 级数据中心的网络架构奠定基础。
可以说,CPO 的出现,标志着互连已不再是独立器件或外围接口,而是系统级设计的核心要素。先进封装与光学深度融合,正在将“互连”转化为“算力”本身。
四、带宽路线图与平台化系统:>200T CPO 的系统工程
先进封装与光引擎的融合,最终指向的是带宽的指数级扩展。报告明确提出:硅光(SiPh)路线图遵循“每代带宽翻倍”的规律,CPO 作为关键形态,正被定位为突破 >200T 级互连带宽 的核心平台。
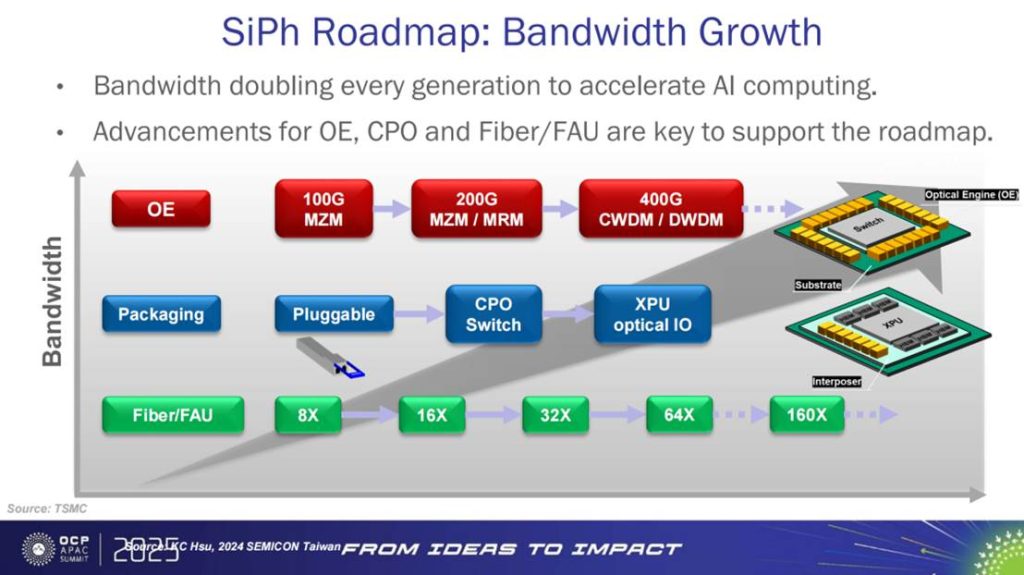
在这一目标下,技术瓶颈从单纯的电学设计,转向 OE(光引擎)、CPO 集成、光纤与 FAU(光纤阵列单元) 的协同突破。带宽不再是单一器件的性能问题,而是系统工程的集体产物。报告强调,OE/CPO/光纤/FAU 的协同进步,决定了带宽曲线能否保持“线性可负担”。
与此同时,TSMC 正将 CPO 纳入更宏观的 Co-Packaged HPC 平台。该平台以 RDL 或硅中介层为底座,可直接嵌入 LSI(逻辑子系统)、IVR(集成电源调节器)、有源芯片 等模块。换句话说,未来的中介层不只是被动互连,而是主动承担电源管理与逻辑分工。这一演进让封装成为真正的 系统底盘,在其上叠合 SoIC®、HBM、Si Photonics 与光纤,形成完整的计算—存储—光 IO 一体化平台。
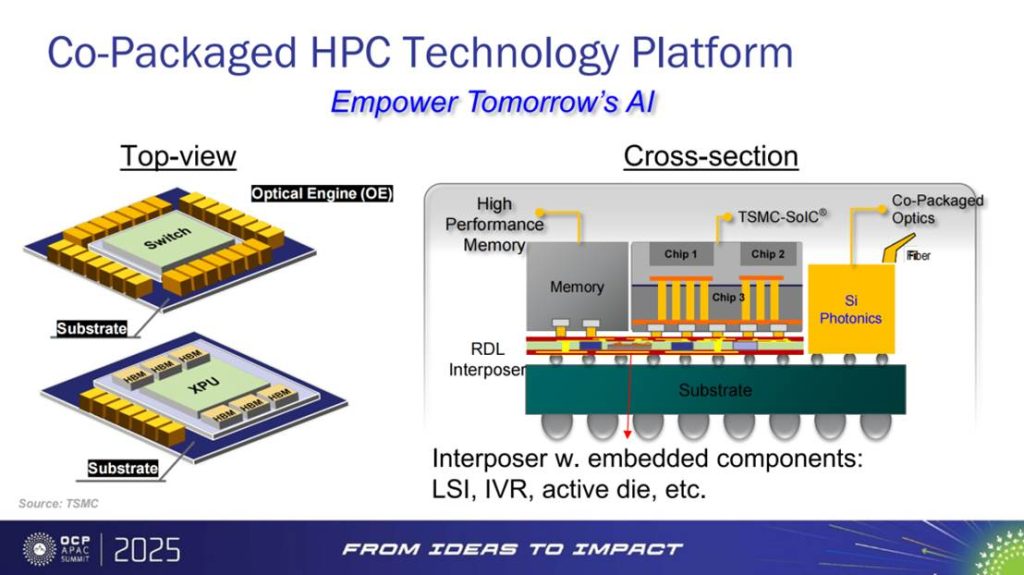
这种平台化思维的价值在于:它将系统设计与封装架构深度绑定。“先进封装不再是连接器件,而是在重构系统边界。” 当带宽突破 200T,传统的分立芯片与外设逻辑已无法满足能效与延迟需求,唯有通过平台化集成,才能将光与电、算力与存储、能耗与带宽统一在一个底层框架内。
可以预见,未来的 HPC/AI 节点,将以 CPO 平台为底座,以异构芯粒为算力单元,以 SiPh 与光纤为互连动脉,构建真正意义上的超算级集群。届时,带宽扩展不再是“单芯片挑战”,而是“系统工程的协奏曲”。
五、产业协同与结语:让能效随带宽“线性可负担”
先进封装与光互连的深度融合,已经成为 HPC/AI 演进的必然趋势。CoWoS® 与 COUPE 的结合,不仅提供了可扩展的中介层底座和紧凑高效的光引擎,更共同塑造了 CPO 的一体化封装形态。这一方案的战略意义在于,它为未来 AI 集群提供了新的能效与时延曲线,确保算力扩展不再受制于互连瓶颈。
然而,CPO 的价值并不仅仅来自技术突破,更取决于 全产业链的协同创新。报告指出,要实现下一代 SiPh CPO 的规模化落地,必须在 设计、制造、封装、光学、光纤阵列(FAU) 等环节实现跨界协同。这不仅是技术课题,更是生态课题。正如一句行业金句所言:“设备与材料的短板,往往是带宽曲线的天花板。”
在这一逻辑下,供应链的角色被重新定义。材料厂商需要突破更低损耗、更高热稳定性的光学与封装材料;设备厂商需提供更高精度、更大尺寸的中介层与光学加工能力;系统厂商则需在架构层面重构算力、存储与光互连的协同设计。换句话说,CPO 不仅是一种封装形态,而是一场涉及全链条的产业变革。
展望未来,随着带宽目标向 >200T CPO 持续推进,功耗与延迟的优化将成为衡量体系竞争力的硬指标。先进封装的价值不再只是延伸摩尔定律,而是通过系统化集成 重构能效与算力的关系。在这个过程中,CoWoS® 与 COUPE 的协同,将成为推动 HPC/AI 进入新纪元的核心驱动力。
一句话总结:让光靠近计算,让能效随带宽线性可负担——这是 CPO 带给行业的真正承诺。