
2024年以来,生成式人工智能从技术突破走向规模化落地,其背后对算力资源的持续拉动,正深刻改变半导体行业的技术路径与产业结构。无论是大型语言模型(LLM)动辄上千亿参数级别的训练需求,还是推理阶段对高能效、低延迟的苛刻要求,AI都在推动芯片设计、制造、封装、互连等多个环节的系统性重构。与此同时,云计算厂商掀起自研AI芯片浪潮,地缘政治加剧产业本地化趋势,封装与硅光子互连成为新性能瓶颈突破口。可以说,AI不仅重塑了芯片需求的数量,更重构了芯片性能、架构与制造主权的定义方式。本报告以“AI应用驱动的半导体行业发展”为主线,系统梳理当前产业趋势、技术演进逻辑与全球竞争格局,揭示新一轮产业洗牌中的核心变量与战略机会。
一、AI驱动的算力爆炸与半导体新需求
在生成式AI浪潮席卷全球的当下,半导体行业正经历一场前所未有的结构性重塑。尤其是大型语言模型(LLM)的迅猛发展,正在深刻改变算力需求格局,重构芯片架构设计逻辑,并推动全球制造能力向先进节点与封装演进。这一趋势不仅重塑技术路线,也带来了产业链重心的迁移与地缘博弈的加剧。
1.1 大模型演进与训练成本激增
从2018年的GPT-1到2024年的LLaMA 3.1,LLM的参数规模已从区区1亿扩展至近2万亿,推动了对计算资源的指数级需求。例如,LLaMA 3.1的训练使用超过20,000颗H100 GPU,成本约达3,000万美元,训练周期接近两个月。与此同时,每一代大模型的训练成本正以10倍速度递增,成为算力基础设施扩张的直接驱动。
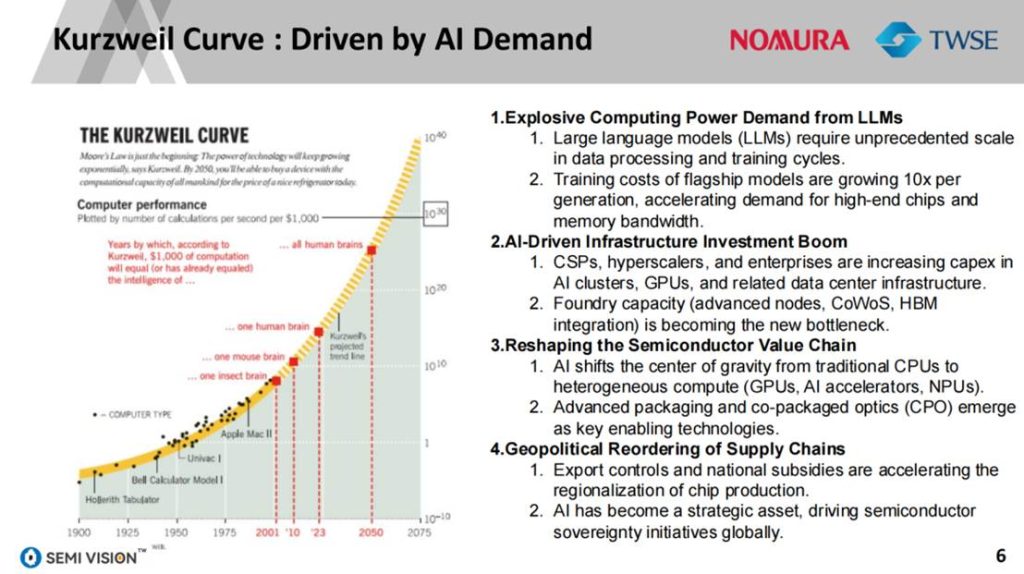
这种算力洪峰不仅推升了高性能GPU和AI加速器的需求,也对高带宽内存(HBM)和芯片互连架构提出更严苛要求。LLaMA-70B的权重模型在FP16精度下高达140GB,仅推理加载就对存储和I/O系统构成巨大压力。

1.2 AI基础设施投资潮与算力瓶颈
面对暴涨的模型训练与推理需求,全球云计算服务提供商(CSP)、超大规模企业和AI初创公司纷纷加大在GPU集群、数据中心和专用芯片上的投资。这一趋势引发了新一轮AI基础设施资本开支高潮。
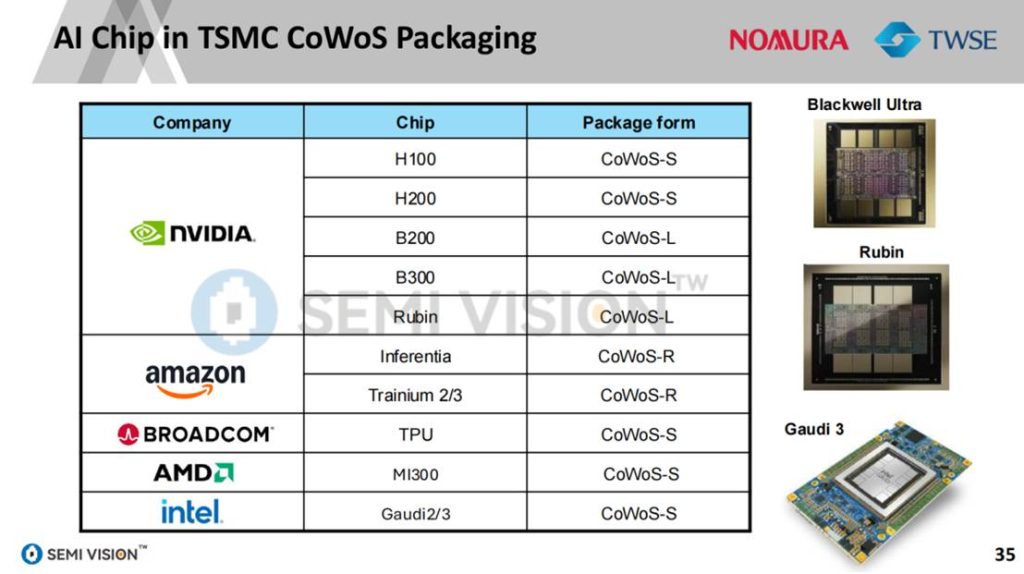
然而,随着先进节点晶圆厂产能吃紧、封装产线满载,制造能力本身正逐步成为系统性能瓶颈。报告指出,CoWoS封装能力、HBM集成良率和先进制程(如N5/N3)的供给限制,已成为AI落地速度的重要制约因素。这促使全球Foundry厂商(尤其是台积电、三星、Intel)竞相扩产并加快技术迭代。
1.3 从CPU到异构计算架构迁移
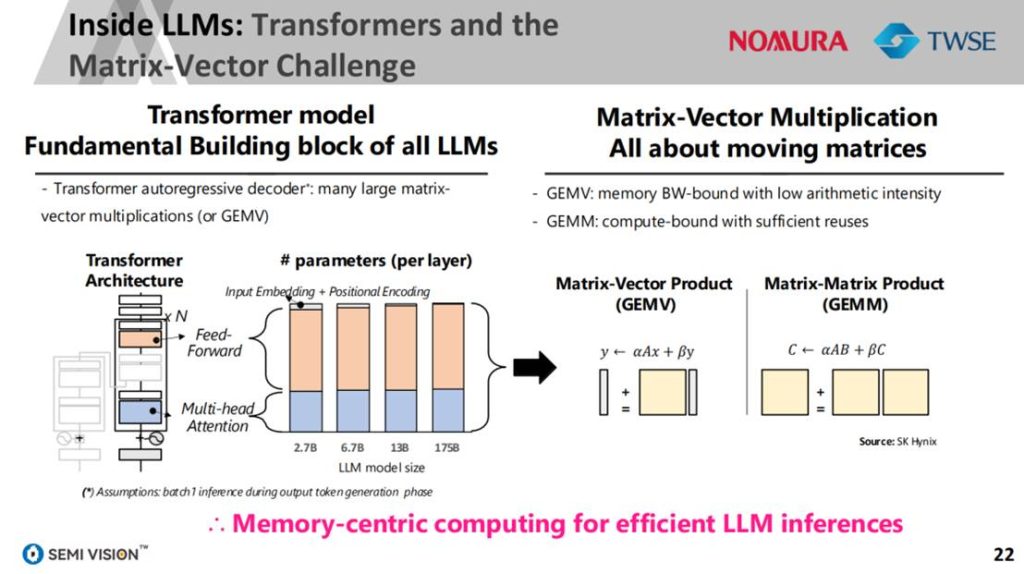
AI模型对计算密集度和内存带宽的极致追求,正加速从传统CPU向GPU、NPU、AI加速器的架构转型。以NVIDIA为代表的GPU平台已成为训练与推理主力,而谷歌TPU、Amazon Trainium、Meta MTIA等自研ASIC也正快速崛起。
此外,随着Transformer架构在LLM中的主导地位确立,其大量矩阵-向量计算操作(GEMV)导致系统整体更依赖高带宽内存和低延迟互连。传统的通用计算逻辑逐渐让位于“异构融合+系统协同”的芯片架构理念,封装与芯粒(chiplet)之间的耦合成为性能跃迁的关键变量。
1.4 地缘政治与AI芯片主权化趋势
AI算力作为国家竞争的核心资源,其战略地位不断上升。各国政府纷纷出台出口管制政策与产业补贴计划,强化本地芯片制造能力。例如,美国通过《芯片与科学法案》吸引台积电、三星在地建厂,同时限制中国获得高端EDA、EUV光刻与AI芯片。
报告明确指出,AI推动的算力竞争已从市场维度上升为国家安全维度。各主要经济体正在推进“芯片主权”战略,以期在AI时代保持技术独立与供应链控制权。这不仅带动了全球制造能力的地区化布局,也加剧了技术标准、产业链控制与IP生态的全球博弈。
二、AI应用催化芯片细分市场重构
生成式AI的广泛落地并未止步于大模型训练,而是全面渗透至推理端、边缘设备乃至垂直行业系统。芯片的“通用性”正被打破,取而代之的是多样化、场景化、系统级的架构演进。从云到端,从人形机器人到自动驾驶,AI应用正以前所未有的方式重构半导体的产品定义与价值链分布。
2.1 云端训练与边缘推理芯片路径分化
大模型(LLM)与小模型(SLM)的分化趋势日益明显,推动AI芯片需求沿“高性能-高能效”两极化发展。一方面,LLM的训练仍依赖GPU集群(如NVIDIA H100/B200)或专用ASIC(如TPU、Trainium),聚焦于性能极限与系统带宽。另一方面,边缘AI则更强调成本、能效与集成度,促成NPU与SoC类芯片的多样化演进。

报告指出,SLM在智能终端、IoT设备中的部署需求激增,带动SoC架构融合AI计算、安全模块与通信接口,典型场景包括智能手机、AR眼镜、车载设备等。这一趋势对封装技术的集成度与芯片异构性提出更高要求。
2.2 人形机器人与自动驾驶推动SoC系统化
AI硬件正走向“类人”系统集成。人形机器人作为高度复杂的智能系统,其对芯片提出“感知+决策+执行”一体化协同需求。报告指出,该类终端将在未来十年成为硅含量最高的设备之一,涵盖CIS传感器、3D感知、决策单元与驱动控制模块,需多类芯片协同工作。

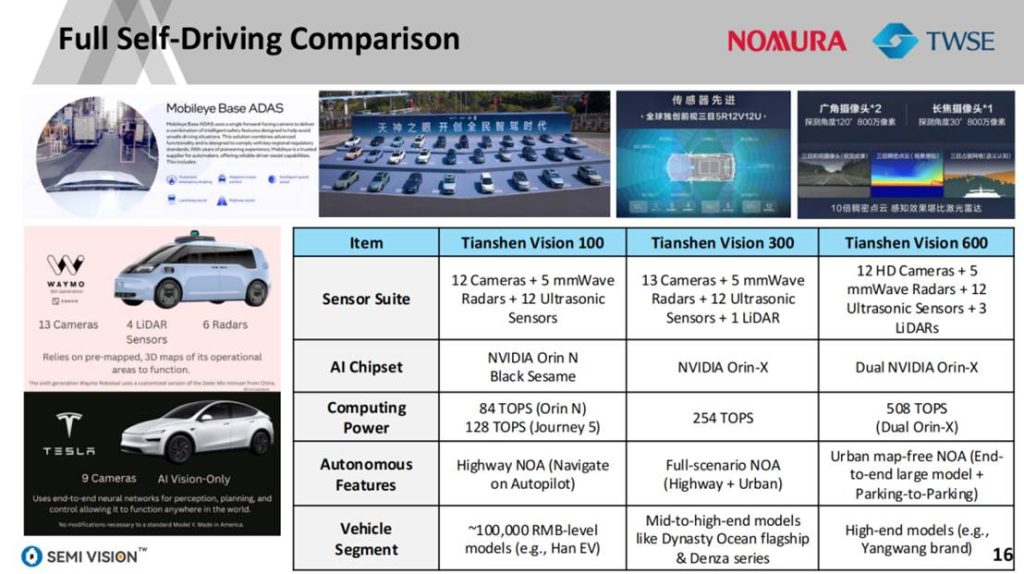
自动驾驶领域同样体现系统集成趋势。以“天神视觉600”为例,其采用双Orin-X芯片组合,算力高达508 TOPS,支持城市级无图导航功能。不同车型配置正按产品定位进行芯片平台模块化组合,从百元级车型到高端旗舰车,芯片架构日趋多样。
2.3 汽车智能化对MCU、CIS、雷达等器件升级要求
AI赋能汽车电子系统的同时,也全面带动各类基础器件的技术跃迁。报告指出,主控SoC将进入N3A与NSA(N3 Superior Automotive)节点,满足算力密度与低功耗要求;而实时控制所需的车规级MCU则向N22/N12节点演进,并广泛整合MRAM或RRAM等非易失存储,提高系统安全性。
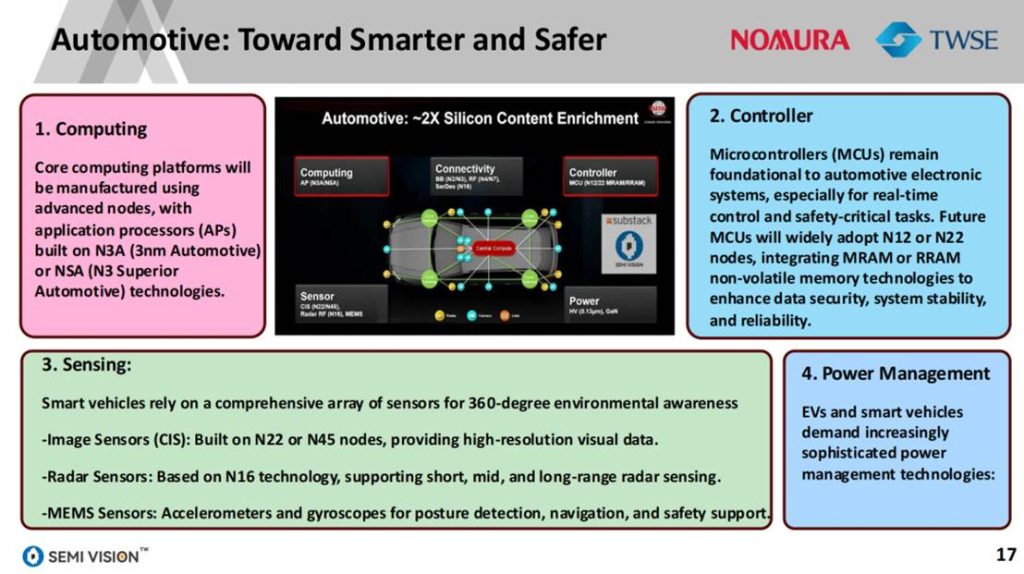
传感端也同步升级:图像传感器(CIS)主攻N22/N45节点,雷达芯片采用N16,MEMS传感器则服务于姿态检测与导航系统。整体趋势为感知分辨率、实时性与数据吞吐能力同步提升,配合整车智能决策系统协同运行。
2.4 AI应用范式重构软件-硬件协同逻辑
AI应用正在推动软件对硬件定义方式的根本变革。一方面,自然语言驱动的“Vibe Coding”模式正将英文变成“最大编程语言”,大幅降低AI开发门槛。另一方面,这一范式也要求底层硬件更高效、更抽象地支持复杂模型运算,特别是在GEMV为主的Transformer模型中,系统设计需围绕内存带宽而非算力密度展。
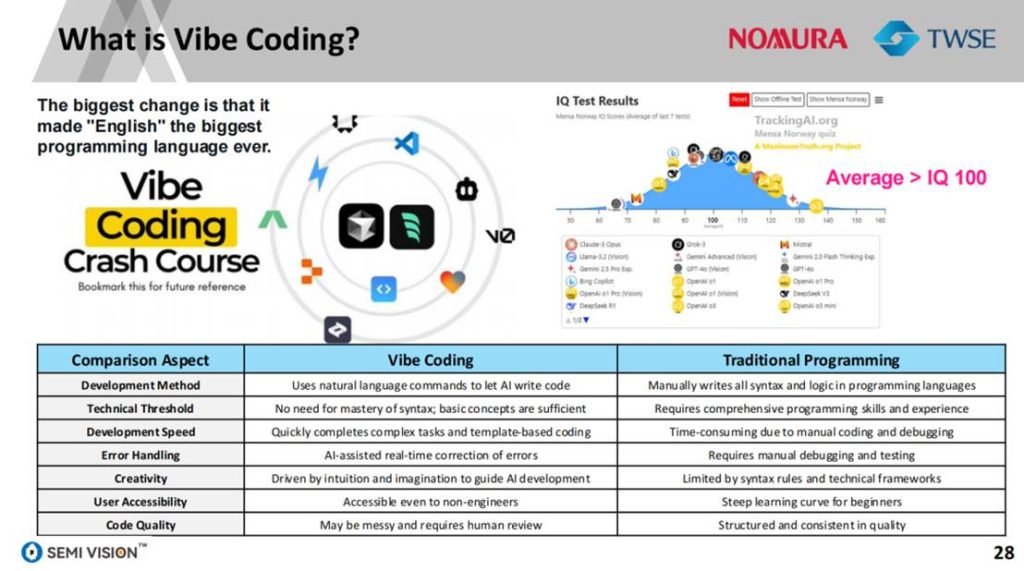
这种“反向定义”带动AI芯片从“算力为王”转向“系统协同”,要求封装、存储、互连、功耗管理一体化提升。芯片的边界不再由硅片物理形态决定,而是由AI应用的需求范式动态塑造。
三、先进封装与光电互连的核心战场
随着AI芯片对带宽、集成度和功耗的要求不断抬升,传统以晶圆制程为主的摩尔定律路径逐渐遇到物理极限。封装不再是“后工序”,而成为系统性能突破的第一战场。先进封装技术与硅光子互连体系,正构成AI芯片下一阶段竞争的核心制高点。
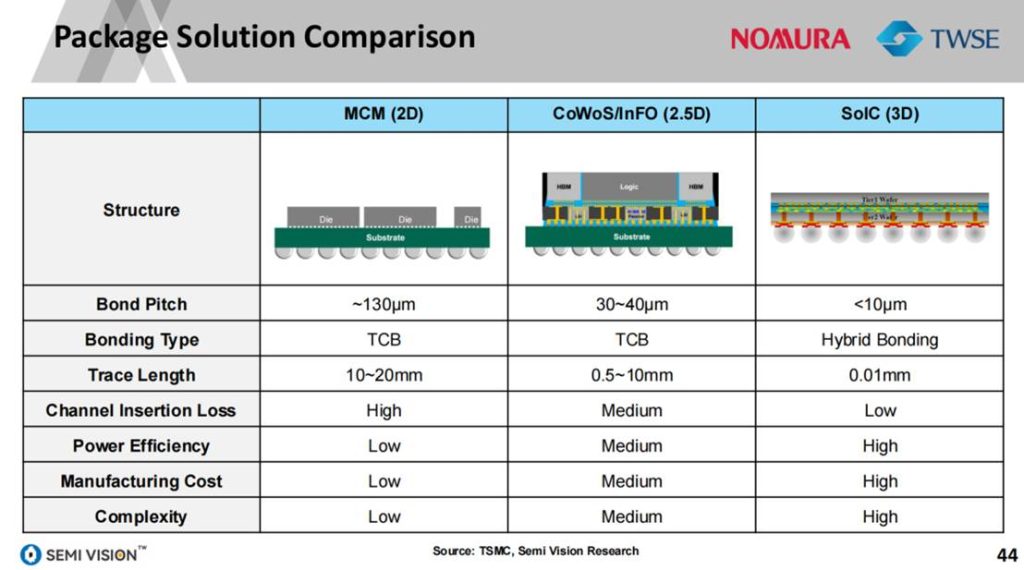
3.1 台积电CoWoS/SoIC迭代路线图
报告详细梳理了台积电先进封装技术的演进路径。从早期的CoWoS-S(如H100)到高密度的CoWoS-L(如B200/B300),不同封装类型结合HBM堆叠数量、SoC节点与传输带宽,实现按需优化。
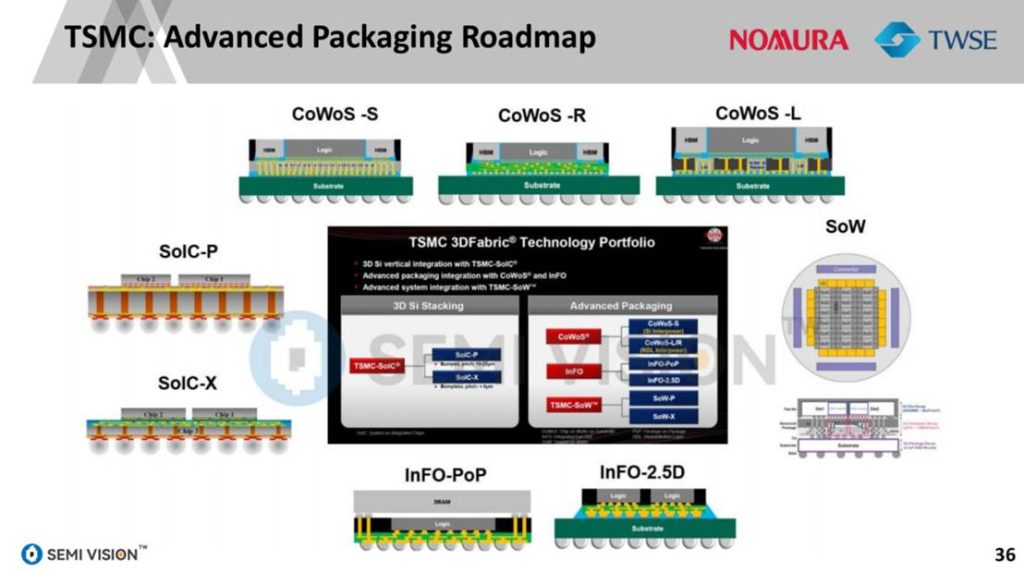
2024年前后,台积电将CoWoS与SoIC并行推进:SoIC(System on Integrated Chips)采用垂直穿孔(TSV)与混合键合技术,实现小于10μm的连接间距,不仅显著提升系统带宽,还降低了功耗和封装尺寸。这使其在AI服务器、HPC、边缘AI等场景中具备显著优势。

3.2 Intel、ASE等厂商差异化封装路径
Intel以Foveros为核心布局3D封装,通过Foveros Direct对标台积电SoIC-X,面向高端服务器与GPU模块。同时,Intel结合EMIB、CPO技术,构建模块化、异构集成的产品体系,试图从“系统级平台”角度对抗台积电的“封装制程一体化”。
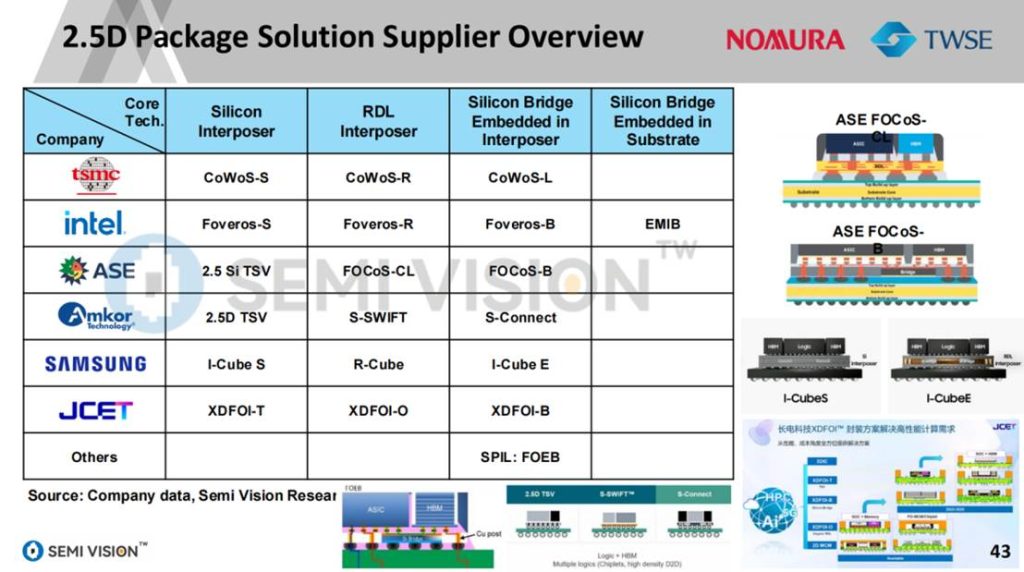
ASE则通过FOCoS(Fan-out Chip on Substrate)家族扩展2.5D封装产品线,主打性价比与规模交付能力,并积极拓展CPO相关封装平台。这种多厂商、多平台共存的生态为芯片设计者提供更大灵活性,也加剧了供应链整合复杂度。
3.3 硅光子技术加速进入主流(CPO)
硅光子技术成为突破系统互连瓶颈的关键。传统铜线互连在100mm传输距离下功耗达30pJ/bit,而通过将光引擎集成至封装层(如Substrate或Interposer),系统功耗可降至2pJ/bit以下,延迟也降至0.05X。
台积电的COUPE平台结合EIC(电子集成电路)与PIC(光子集成电路),通过光栅耦合(COUPE-GC)或边缘耦合(COUPE-EC)实现与封装层的集成。多数CSP厂商倾向于选择兼容性更强、测试更方便的GC方案。NVIDIA在Quantum-X800交换机中即已采用CPO封装,预示未来AI集群间互连全面迈入光子时代。
3.4 光电耦合、封装标准与自动测试体系成熟
CPO平台的大规模落地离不开标准化与测试能力提升。报告指出,TSMC与产业伙伴已建立完整的EWAT/OWAT自动化测试流程,覆盖暗电流、调制器RC常数、加热器电阻等关键指标。同时,O-band光子PDK也已支持从设计、仿真到工艺集成全流程,为客户提供系统级设计能力。
COUPE方案在系统能效、带宽密度、耦合精度等维度全面优于传统μBump封装:能耗仅为19%,带宽密度提升近38倍,进一步强化其在未来AI系统设计中的基础地位。
四、制造版图重构与全球节点竞赛
在AI算力需求持续扩张、芯片架构复杂度跃升的背景下,全球半导体制造体系正被重新划分。建厂成本、技术节点演进速度、自主可控程度,正在成为决定国家产业竞争力的关键变量。与此同时,主导AI生态的云厂商也不再满足于采购标准化GPU,正逐步成为半导体价值链的重要“定义者”。
4.1 芯片制造成本对比:台积电台湾 vs 美国建厂
报告详细对比了台积电在台湾与美国建厂的成本结构差异。美国厂房在设备运输(尤其是EUV设备)、人力安装、洁净室施工等方面成本明显高于台湾本土,导致整体成本高出约33%–45%。
尽管台积电已宣布在美国建设多个N4/N3/N2节点产线,但初期产能利用率与成本效率存在显著劣势。这可能削弱其长期在美扩产意愿,也折射出先进制程全球化部署的现实挑战。
4.2 主要Foundry节点路线图对比
全球三大先进制程玩家——台积电、三星、Intel正围绕2nm以下节点展开激烈竞争。
- 台积电推进至N2/N2P节点,采用GAA架构,同时强化SoIC/CoWoS协同。
- 三星推进3GAP → SF2 → SF1.4演进,并力图缩短与TSMC在良率和封装上的差距。
- Intel则通过Intel 3 → 20A → 18A → 14A的迭代,配合Foveros 3D封装,实现制程/封装一体化路线。
整体来看,先进制程正从“单一节点竞赛”演进为“制程+封装+系统协同”立体竞争。
4.3 云厂商推动AI芯片自研潮与ASIC市场扩张
面对AI芯片成本高涨与NVIDIA供应受限,AWS、Google、Meta、Microsoft等云服务巨头正加速自研AI芯片:
- AWS布局Trainium、Inferentia系列ASIC,均交由台积电代工(7nm → 5nm → 3nm)
- Google的TPU系列已更新至V6版本,预计2025年上线3nm制程。
- Meta自研MTIA,搭配自有大模型部署,降低对H100的依赖。
根据报告统计,2024年各平台ASIC芯片出货市占率已达23%–76%不等,取代部分NVIDIA市场份额。这种趋势强化了Foundry与云厂商间的技术捆绑关系,也对EDA/IP生态提出新挑战。
4.4 高端制造能力重构产业权力格局
AI芯片竞争正在从“芯片性能”转向“制造平台主导权”的争夺。具备先进制程、先进封装能力的Foundry厂商(如台积电),正成为AI产业的“新平台”。无论是H100、TPU,还是未来B系列或MTIA系列芯片,其核心差异化能力已深度嵌入Foundry层。
同时,封测厂、光子互连供应链也正成为AI系统性能的关键变量。在这一结构中,传统芯片设计公司如NVIDIA将更多以系统整合者与IP聚合者的身份存在,而Foundry则将控制关键资源:工艺节点、封装产线、平台化生态。
这标志着芯片产业正由“设计主导”向“制造主导”转变,全球产业权力格局也随之重构。