与其他全开源模型相比,性能提升2-5倍。
小参数模型也进入了 R1 时代,这次开源出新技术的是 Meta。
本周,Meta AI 团队正式发布了 MobileLLM-R1。
- HuggingFace 链接:https://huggingface.co/collections/facebook/mobilellm-r1-68c4597b104fac45f28f448e
- 试用链接:https://huggingface.co/spaces/akhaliq/MobileLLM-R1-950M
这是 MobileLLM 的全新高效推理模型系列,包含两类模型:基础模型 MobileLLM-R1-140M-base、MobileLLM-R1-360M-base、MobileLLM-R1-950M-base 和它们相应的最终模型版。
它们不是通用的聊天模型,而是监督微调 (SFT) 模型,专门针对数学、编程(Python、C++)和科学问题进行训练。
除了模型本身之外,Meta 还发布了完整的训练方案和数据源,以确保可重复性并支持进一步的研究。
值得注意的是,该系列参数最大的 MobileLLM-R1 950M 模型仅使用约 2T 高质量 token 进行预训练,总训练 token 量少于 5T,但在 MATH、GSM8K、MMLU 和 LiveCodeBench 基准测试中,其性能与使用 36T token 进行训练的 Qwen3 0.6B 相当或更佳。
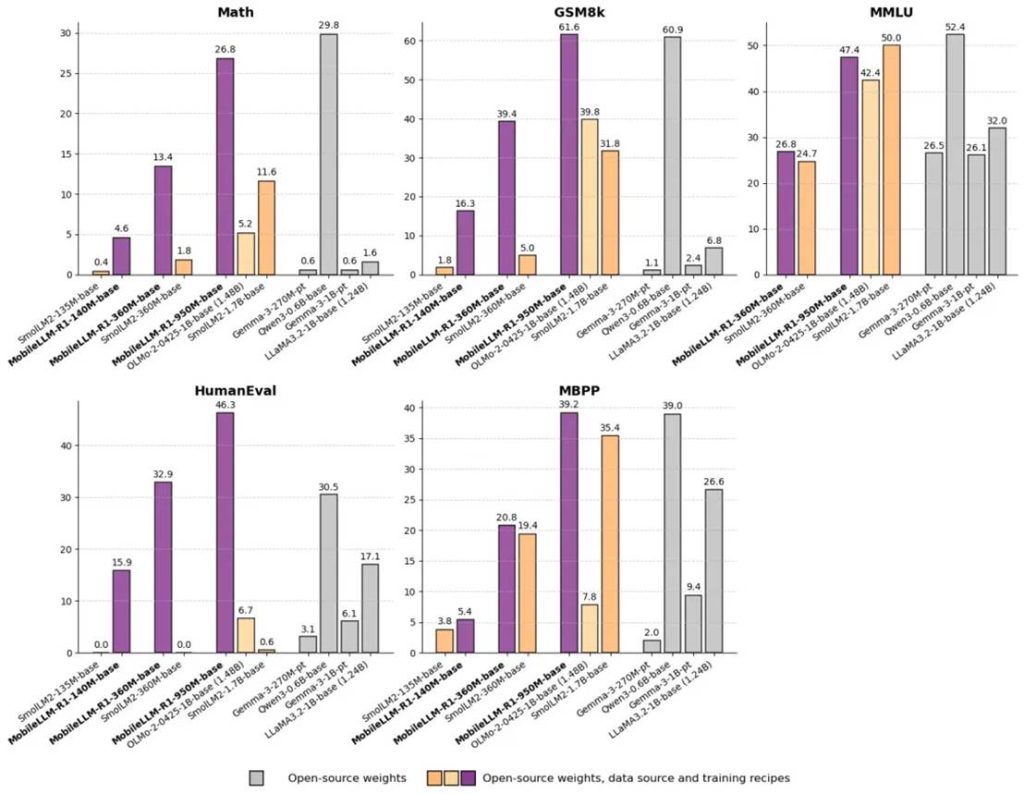
与现有的完全开源模型相比,尽管参数规模明显更小,MobileLLM-R1 950M 模型在 MATH 基准上的准确率也比 Olmo 1.24B 模型高出约五倍,比 SmolLM2 1.7B 模型高出约两倍。此外,MobileLLM-R1 950M 在编码基准测试中的表现远超 Olmo 1.24B 和 SmolLM2 1.7B ,在完全开源模型中创下了新的最高水平。
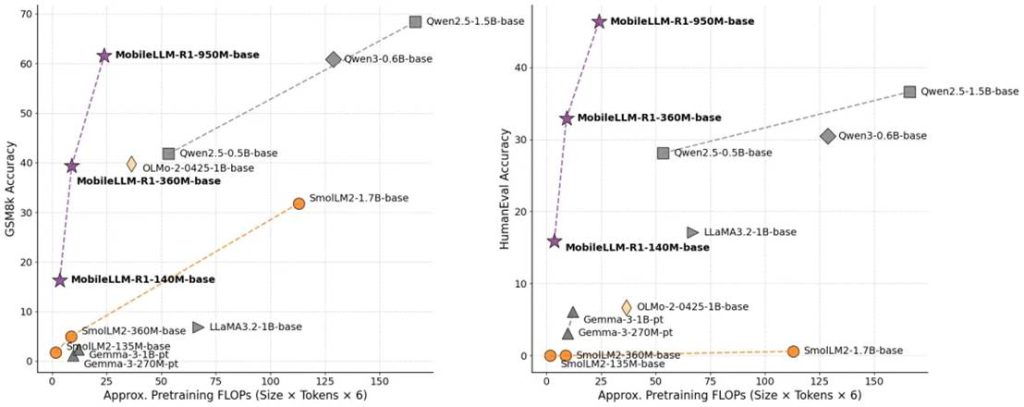
Token 效率的比较如下:
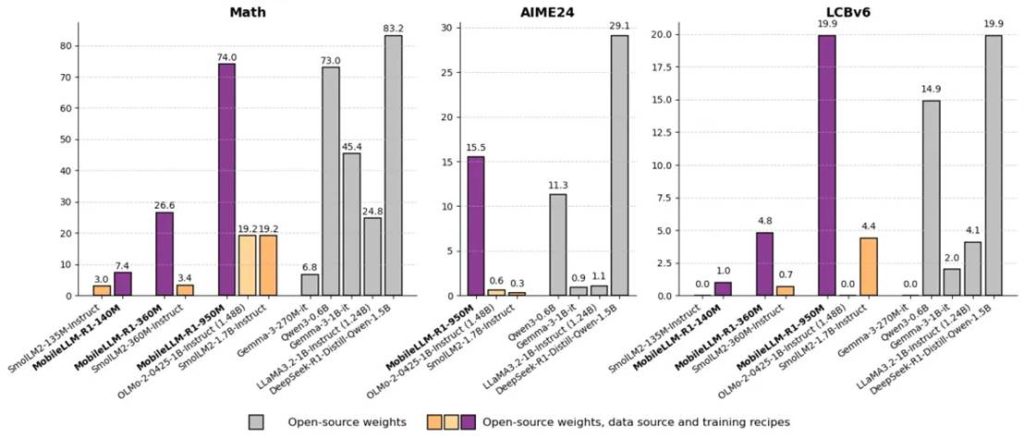
后训练比较:
模型架构:
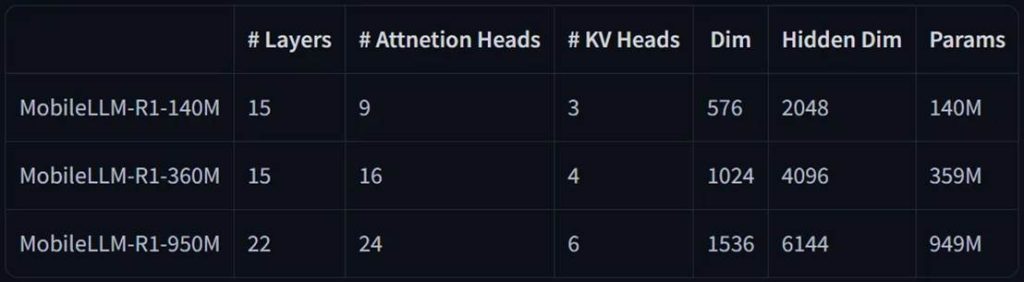
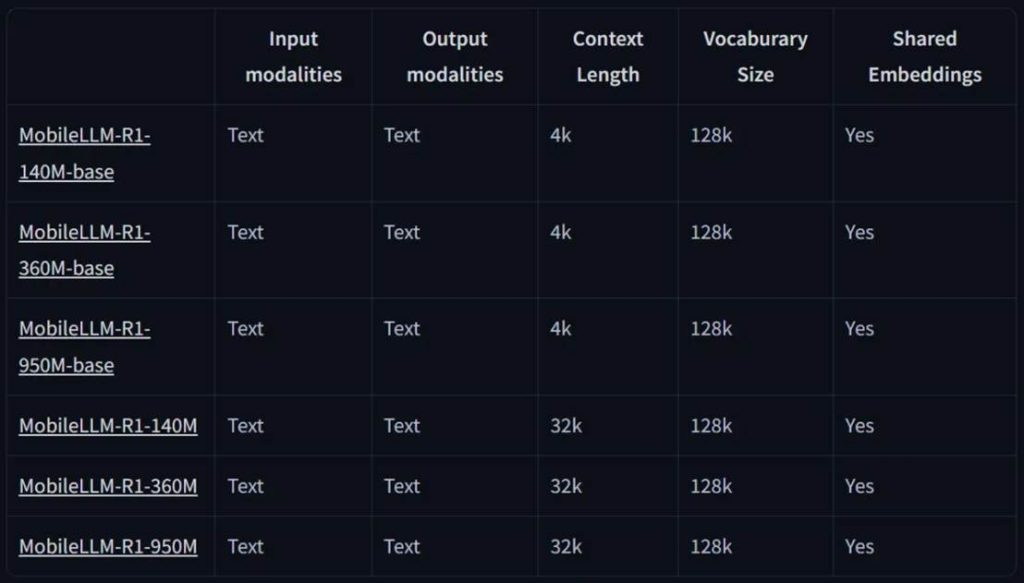
MobileLLM-R1 的发布引起了机器学习社区的讨论。人们欢迎通义、Meta 等顶尖大模型团队基于小体量模型的探索。这一方向的训练成本较为低廉,可以更加方便尝试各类最新论文提出的技术,更重要的是,模型体量的下降也意味着它可以覆盖更多端侧设备,实现更大面积的落地。
随着训练成本普遍下降,我们将会得到更好的模型。