1. 痛点与挑战
过去两年,大模型技术在文本生成、图像理解、代码开发等通用领域实现跨越式突破,技术成熟度与落地能力已得到市场广泛验证。然而,在制造业这一强调专业知识壁垒、场景复杂度高、数据格式特殊的垂直领域,大模型能否突破 “通用能力” 与 “行业需求” 的适配瓶颈,真正嵌入工程链路并提升核心效率,始终是产业界与技术界共同关注的核心议题。
在制造业核心的图纸检索场景中,设计工程师面临着更为具体的效率痛点:为完成产品迭代、工艺优化或故障排查,往往需要从成百上千份包含零件图、装配图的历史图纸中,精准定位含特定零部件规格、材料牌号或技术要求(如公差、热处理标准)的文件。传统模式下,这一过程依赖人工按目录翻阅、凭经验筛选,或仅通过单一关键词匹配检索,不仅耗时耗力(单次检索常需数小时甚至数天),更易因信息遗漏导致制造偏差;而多模态大模型与智能体技术的协同发展,正打破这一僵局 —— 通过图纸自动矢量化解析、专业术语语义映射、跨模态检索匹配等技术,让 “以自然语言描述直接定位目标图纸” 从技术构想逐步走向工程实践。
面对不同厂商推出的大模型,谁能在图纸解析与检索的复杂任务中脱颖而出?
首先我们选择了测试平台部署在惠普Z8 Fury G5台式工作站上, Z8 Fury G5能够高效处理每小时数TB级别的数据。这种强大的计算能力支持复杂的生成式AI模型运行,能够显著提升工程的效率和决策准确性。

测试平台部署其他建议,针对中小参数规模开源模型的评测,在惠普ZBook X上也可以实现,惠普ZBook X搭载英特尔酷睿Ultra9的英特尔vPro,酷睿Ultra 200H,全能AI PC 商务硬实力。
测试平台可以实现端侧模型对 “性能、稳定性、扩展性” 的三重平衡要求,为不同架构开源模型的能效比、推理精度、并发处理能力等核心指标提供了可靠的硬件支撑。
尤其搭载英特尔酷睿 Ultra9 vPro 处理器,凭借专为 AI 负载优化的异构计算架构与端侧评测场景深度适配的硬件设计,Ultra9 vPro 的多核性能24 核 24 线程 +与 13 TOPS NPU 算力形成协同,可高效支撑从 7B 到 12B 参数规模开源模型的本地推理。


其次我们选择了以下五款开源大模型,在真实平台中展开了一场“图纸智能助手”的大比拼:meta-llama/Llama-3.1-8B-Instruct,Google/gemma-3-12b,deepseek-ai/DeepSeek-R1-Distill-Qwen-7B,Qwen/Qwen2.5-7B-Instruct,openbmb/MiniCPM4.1-8B。各个模型的关注度和下载量如表1所示。
表1 不同开源大模型在Huggingface和ModelScope上的关注度和下载量(统计于2025.9.23)
| 模型名称 | Huggingface 星标数 | Hugging face 下载量 | ModelScope 下载量 |
| Llama-3.1-8B-Instruct | 62.2k | 7.09M | 219.6k |
| gemma-3-12b-it | 30.4k | 504k | 14.3k |
| DeepSeek-R1-Distill-Qwen-7B | 96.5k | 814k | 574.3k |
| Qwen2.5-7B-Instruct | 50.6k | 6.89M | 3.8M |
| MiniCPM4.1-8B | 2.05k | 4.02k | 2.4k |
从数据中可以看出,当前大语言模型市场格局主要由 Llama-3.1-8B-Instruct 和 Qwen2.5-7B-Instruct 两款模型主导,它们凭借数百万级别的下载量,确立了显著的市场领先地位。Llama-3.1 在以Hugging Face为代表的国际开发者社区中表现出强大的影响力,而 Qwen2.5 则通过在Hugging Face和ModelScope两大主流平台上的均衡且卓越的表现,实现了跨市场的广泛覆盖。此外,DeepSeek-R1-Distill-Qwen-7B 以最高的社区关注度指标脱颖而出,这表明市场竞争的维度已超越单纯的下载量,模型的开发者生态与社区吸引力同样构成了其核心竞争力的关键部分。
在本次比拼的平台“图纸智能助手”是一个能够基于大语言模型的将自然语言转换成SQL语句,实现端到端的智能检索助手,用户仅需输入自然语言即可精确定位目标图纸。大模型在这个助手中起到两个作用:
1.查询用户意图,解析用户输入的自然语言,将其转化为键值对的形式;
2.将解构完成的键值对转化成SQL语句进行检索。
2. 实验平台与方法
2.1 实验平台架构
本次评测围绕一个图纸检索平台,平台主要包含两个功能:
- 图纸处理:
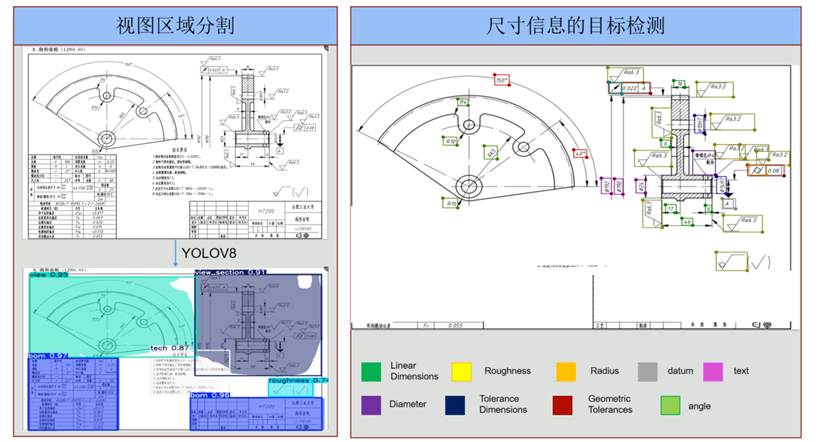
- 1.使用目标检测模型(如 YOLO)对图纸进行区域分割(如三视图、BOM明细栏、技术要求)。
- 2.借助 OCR 或多模态大模型提取文本信息。
- 3.将结果结构化为键值对(如“零件名称-轴承”“材料-Q235钢”)的形式存储值数据库中。
- 图纸检索:
- 1.构建一个基于大模型的 text2sql 智能体。
- 2.用户通过自然语言输入(如“找出所有使用Q235钢的零件图纸”)。
- 3.智能体将问题解构为键值对的形式(如“材料-Q235钢”),然后转化为 SQL语句查询,从数据库检索相关图纸。
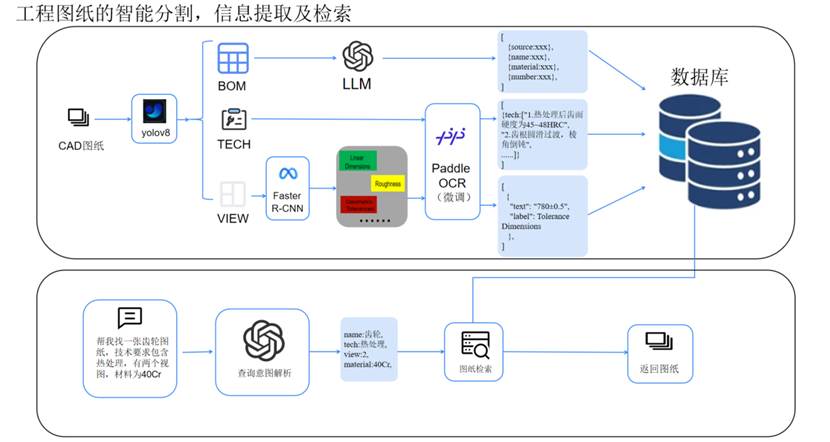
本次评测目标主要聚焦于图纸检索部分,考察不同大模型在解构自然语言与生成sql语句进行检索两大任务中的表现。
2.2评测维度与指标体系
为全面衡量模型表现,本次评测设置了三个核心维度:
- 图纸文本解析准确率:衡量模型在提取 BOM、技术要求等关键信息时的正确率。指标为Precision、Recall、F1。其中Precision是精确率,衡量模型在提取的所有关键信息中提取正确的信息的数量,Precision越高,模型准确率越高;Recall代表召回率,衡量模型提取的信息在所有正确信息中的占比,同样也是Recall越高,模型准确率越高。最后的综合指标用F1来评测,F1作为Precision与Recall的调和平均数,计算公式为F1 = 2 × (Precision × Recall) / (Precision + Recall),同样的F1越高,精确率越高。
- 检索一致性(text2sql 准确率):衡量自然语言描述转化为 SQL 查询的正确性。指标为执行结果 Top-1 命中率。Top-1 命中率为大模型在多次生成SQL语句是,第一次生成的答案就是正确的概率。
- 平台整体体验(效率与稳定性):考察模型在真实场景中处理速度、输出稳定性。指标为平均响应时延(Latency)、显存占用(VRAM)、GPU利用率。
测试用例示例:
- 输入:「找出材料为铝合金6061、表面处理为阳极氧化、厚度在2-5mm之间的板件图纸」。
- 标准答案:{ “材料”: “铝合金6061”, “表面处理”: “阳极氧化”, “厚度”: “2-5mm”, “零件类型”: “板件”}
3. 实验结果与分析
平台部署在惠普Z8 Fury G5台式工作站上确保了评测结果的稳定性和可比性。
配置表:生产力工具HP Z8 Fury G5 台式工作站配置信息
HP Z8 FURY G5 台式工作站配置
处理器 英特尔®志强®W7-3465X 28C 300W
内存 512GB (8x64GB) DDR5 4800 ECC PR
硬盘 2TB 2280 PCIe4x4 TLC

3.1 各指标评测结果
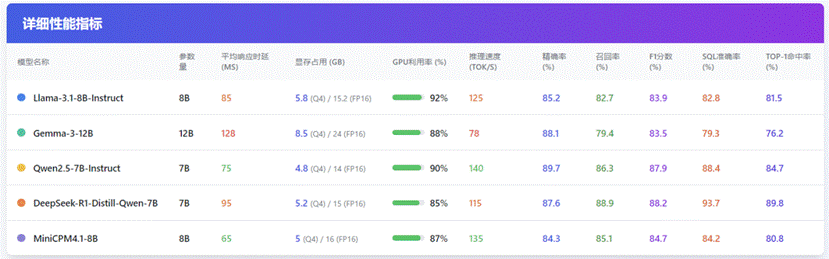
图2 综合评测结果
技术团队在Z8 Fury G5台式工作站强劲的英特尔®至强®W处理器的助力下,可以提供强大的图形处理能力和并行计算能力,实现对本次测试的高效处理和分析。
在综合表现上,国产大模型 Qwen2.5-7B-Instruct 与 DeepSeek-R1-Distill-Qwen-7B 表现领先,其中DeepSeek-R1-Distill-Qwen-7B 在 SQL 转换的准确率和命中率上突出,而 Llama-3.1-8B 与 MiniCPM4.1-8B 在复杂查询中稍显不足。但是从效率维度来看,MiniCPM4.1 的响应时延最低,适合大规模并发场景,更适合在开发阶段使用。
3.2 图纸检索准确率
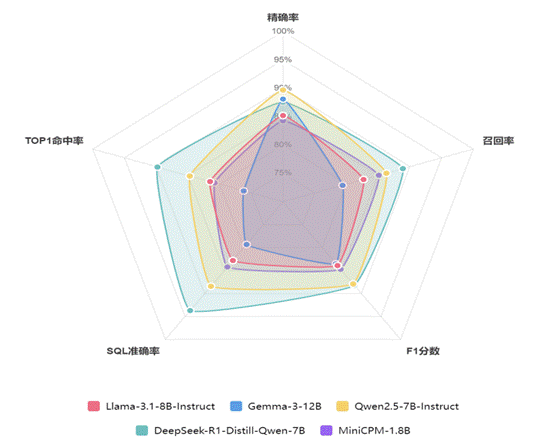
图3 图纸解析检索准确率
从图3可以看出Deepsee-R1在三个维度上都表现优异,形成的多边形面积较大且相对均衡,显示出全面而稳定的性能,Qwen2.5在各维度相对稳定,形成的图形较为规整,是可靠的替代选择,Llama 和 MiniCPM4.1 在SQL生成方面相对较弱.
3.3模型的效率与稳定性
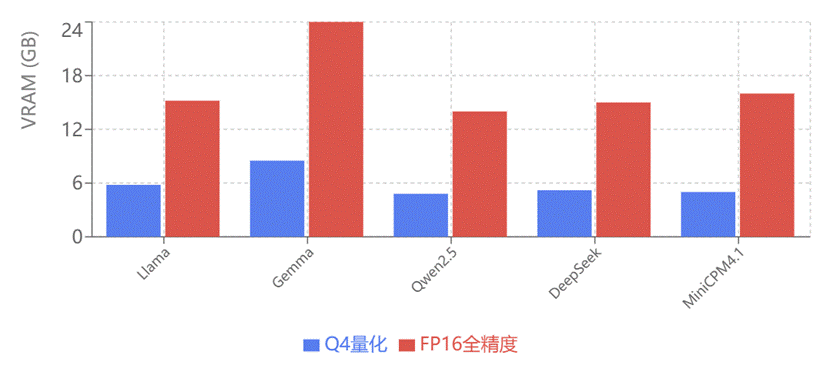
图4 显存占用对比
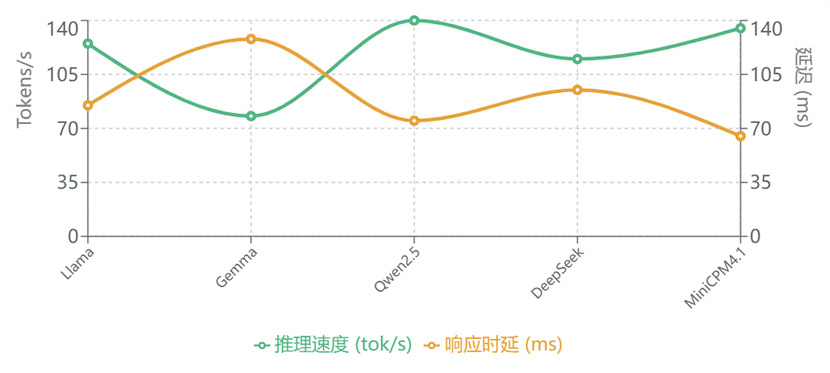
图5 推理性能对比
从图4图5可以看出Qwen2.5-7B-Instruct在准确性、推理速度、资源占用三方面都表现优异,推理速度最快(140 tok/s),显存占用合理(14GB/5GB),是图纸检索应用的最佳选择,deepseek的性能虽劣于Qwen,但是在查询图纸的准确率上相对稳定,是个替换选择,这一综合分析表明,国产大模型不仅在专业能力上具备竞争优势,在工程化部署方面也更加实用,为制造业AI应用的规模化落地提供了有力支撑。
3.4 评测案例
(1) 案例一:单一条件查询
1.测试输入:「查找所有使用45钢的零件图纸」
| 模型 | 生成SQL | 执行结果 | 命中率 |
| Qwen2.5 | SELECT * FROM drawings WHERE material = '45钢' | 完全正确 | 96% |
| DeepSeek-R1 | SELECT * FROM drawings WHERE material LIKE '%45%' | 完全正确 | 94% |
| Gemma-3-12B | SELECT * FROM drawings WHERE material = '45 Steel' | 部分正确 | 78% |
| Llama-3.1 | SELECT * FROM drawings WHERE material_type = 'steel' AND material_grade = '45' | 部分正确 | 82% |
| MiniCPM4.1 | SELECT * FROM drawings WHERE material = '45钢' | 完全正确 | 89% |
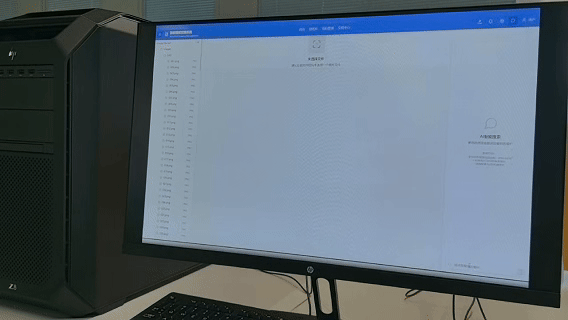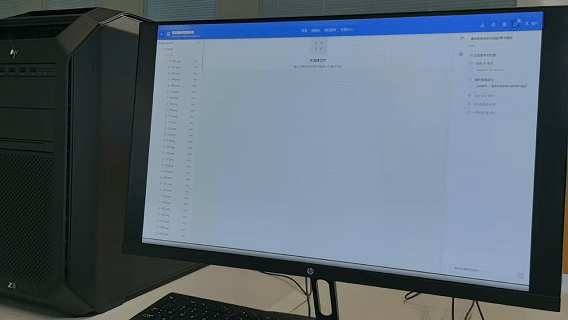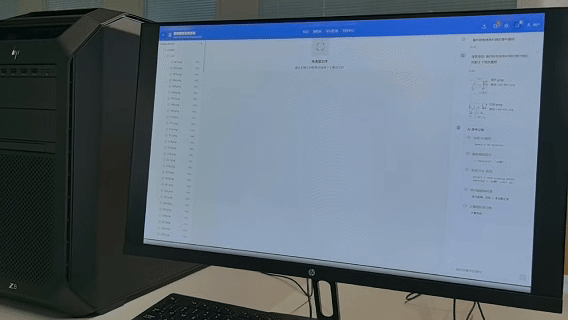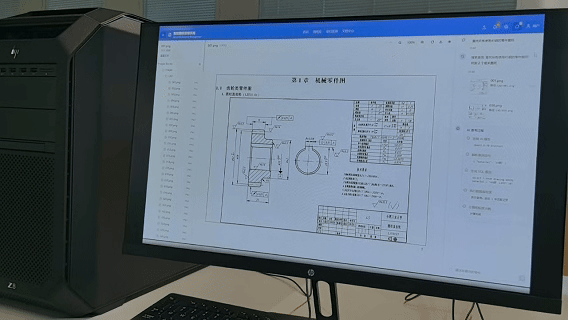
动画内容:查找所有使用45钢的零件图纸
2.测试输入:「查找所有表面处理为阳极氧化的零件图纸」
| 模型 | 生成SQL | 执行结果 | 命中率 |
| Qwen2.5 | SELECT * FROM drawings WHERE surface_treatment = ‘阳极氧化’ | 完全正确 | 93% |
| DeepSeek-R1 | SELECT * FROM drawings WHERE surface_treatment LIKE ‘%阳极氧化%’ OR surface_treatment LIKE ‘%anodizing%’` | 完全正确 | 98% |
| Gemma-3-12B | SELECT * FROM drawings WHERE treatment_type = ‘anodizing | 部分正确 | 72% |
| Llama-3.1 | SELECT * FROM drawings WHERE surface_finish = ‘anodized’ | 部分正确 | 75% |
| MiniCPM4.1 | SELECT * FROM drawings WHERE surface_treatment = ‘阳极氧化’ | 完全正确 | 86% |
(2) 案例二:复合逻辑查询
1.测试输入:「找出使用HT200且热处理硬度小于HRC60的零件图纸」
各模型表现:
| 模型 | 生成SQL | 关键问题 | 执行结果 |
| Qwen2.5 | SELECT * FROM drawings WHERE material LIKE ‘%HT200%’ AND heat_treatment_hardness < 60 | 字段映射和数值提取准确 | 92%正确 |
| DeepSeek-R1 | SELECT * FROM drawings WHERE material = ‘HT200’ AND hardness < ‘HRC60’ | 硬度字段类型处理需要优化 | 85%正确 |
| Gemma-3-12B | SELECT * FROM drawings WHERE material = ‘HT200′ AND hardness_hrc < 60 | 中英文混用影响匹配 | 76%正确 |
| Llama-3.1 | SELECT * FROM drawings WHERE material = ‘HT200’ AND hardness < 60 | 遗漏硬度单位信息 | 81%正确 |
| MiniCPM4.1 | SELECT * FROM drawings WHERE material = ‘HT200’ | 遗漏热处理硬度条件 | 45%正确 |
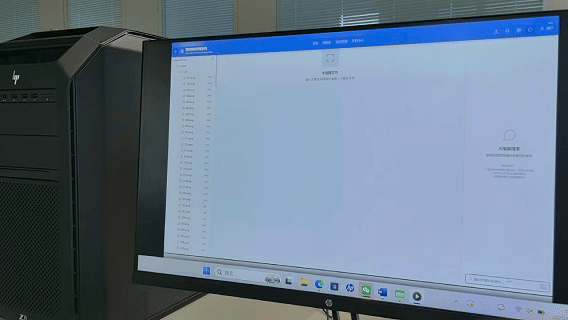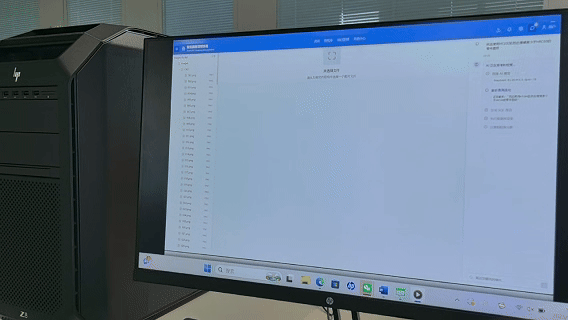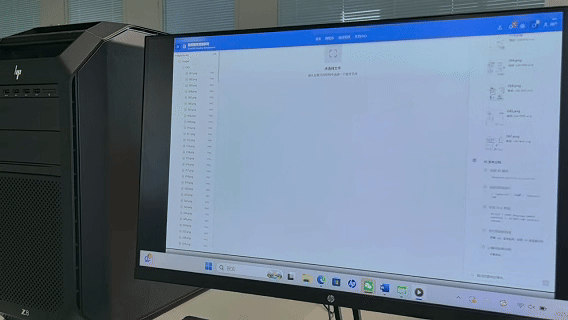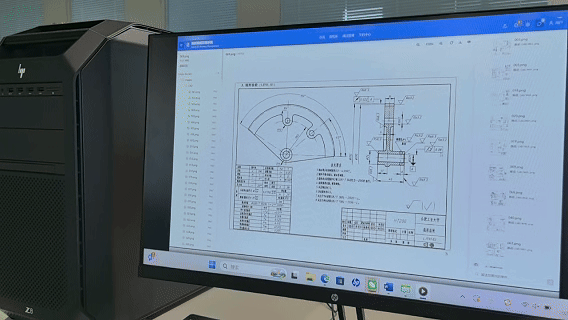
动画内容:找出使用HT200且热处理硬度小于HRC60的零件图纸、
2.测试输入:「查找材料为45钢,且经过调质处理,直径大于30mm的轴类零件」
各模型表现:
| 模型 | 生成SQL | 关键问题 | 执行结果 |
| Qwen2.5 | SELECT * FROM drawings WHERE material = ’45钢’ AND heat_treatment = ‘调质处理’ AND diameter > 30 AND component_type = ‘轴类’ | 术语规范化处理,字段映射清晰 | 90%正确 |
| DeepSeek-R1 | SELECT * FROM drawings WHERE material = ’45钢’ AND heat_treatment = ‘调质’ AND diameter > 30 AND part_type LIKE ‘%轴%’ | 四重条件完整识别,专业术语映射准确 | 96%正确 |
| Gemma-3-12B | SELECT * FROM drawings WHERE steel_grade = ’45’ AND treatment = ‘Q&T’ AND size > 30 | 多个字段映射错误,术语缩写不规范 | 66%正确 |
| Llama-3.1 | SELECT * FROM drawings WHERE material = ‘carbon steel 45’ AND heat_treatment = ‘quenching and tempering’ AND diameter > 30 | 遗漏零件类型条件,术语英译 | 75%正确 |
| MiniCPM4.1 | SELECT * FROM drawings WHERE material = ’45钢’ AND heat_treatment = ‘调质’ AND diameter > 30` | 遗漏零件类型条件 | 62%正确 |
4. 总结与展望
本次针对五款开源大模型在图纸检索任务中的综合评测,揭示了当前大模型在制造业专业场景应用的真实水平和发展态势。评测结果显示,国产大模型在垂直领域应用上已展现出明显的竞争优势,特别是在处理中文工程术语和复杂查询逻辑方面表现突出。
- 本次评测表明,大模型在制造业专业应用中已经具备了实用化的基础能力,特别是国产大模型在中文工程环境下展现出的优异表现,为我国制造业的智能化转型提供了重要的技术支撑。
- 随着技术的不断进步和应用场景的深度拓展,我们有理由相信,基于大模型的智能制造助手将成为未来工程设计的标配工具,极大提升设计效率、降低设计成本,推动制造业向更高质量、更高效率的智能制造时代迈进。
- 面向未来,我们建议制造企业积极拥抱AI技术变革,选择适合自身需求的大模型解决方案,在数字化转型的道路上抢占先机,为企业的可持续发展注入强劲的智能化动力。